Trong phần trước chúng ta đã cùng tìm hiểu về mô hình, cũng như tại sao nên sử dụng Kafka. Bài viết này chúng ta sẽ khám phá cách Kafka hoạt động, kiến trúc của nó và các thành phần chính.

Tin tức, hướng dẫn và chia sẻ về công nghệ
Trong phần trước chúng ta đã cùng tìm hiểu về mô hình, cũng như tại sao nên sử dụng Kafka. Bài viết này chúng ta sẽ khám phá cách Kafka hoạt động, kiến trúc của nó và các thành phần chính.
Apache Kafka đã trở thành công cụ hàng đầu trong xử lý dữ liệu thời gian thực và hệ thống phân tán. Bài viết này giải thích chi tiết về Kafka, cách thức hoạt động, ứng dụng thực tế, và lý do bạn nên sử dụng nó.

Trong kỷ nguyên dữ liệu lớn (Big Data), việc xử lý dữ liệu nhanh chóng, hiệu quả và đáng tin cậy trở thành nhu cầu thiết yếu của các doanh nghiệp. Hệ thống xử lý dữ liệu phân tán (Distributed Data Processing System) là giải pháp hàng đầu để giải quyết vấn đề này. Bằng cách phân tán khối lượng công việc xử lý dữ liệu trên nhiều máy tính khác nhau, hệ thống này mang lại hiệu suất cao, khả năng mở rộng linh hoạt và độ tin cậy vượt trội.
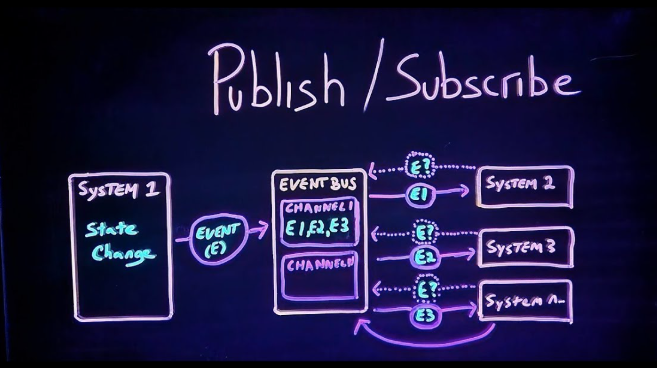
Publisher-Subscriber (Pub-Sub) là một mô hình giao tiếp không đồng bộ, trong đó Publisher (Người xuất bản) gửi thông điệp mà không cần biết ai sẽ nhận, và Subscriber (Người đăng ký) chỉ nhận thông điệp mà họ quan tâm thông qua một hệ thống trung gian gọi là Message Broker.
© 2025 Trang tin tức từ Cloud365 – Nhân Hòa
Theme by Anders Noren — Up ↑
Recent Comments