Trong phần trước chúng ta đã cùng tìm hiểu về mô hình, cũng như tại sao nên sử dụng Kafka. Bài viết này chúng ta sẽ khám phá cách Kafka hoạt động, kiến trúc của nó và các thành phần chính.

Tin tức, hướng dẫn và chia sẻ về công nghệ
Trong phần trước chúng ta đã cùng tìm hiểu về mô hình, cũng như tại sao nên sử dụng Kafka. Bài viết này chúng ta sẽ khám phá cách Kafka hoạt động, kiến trúc của nó và các thành phần chính.
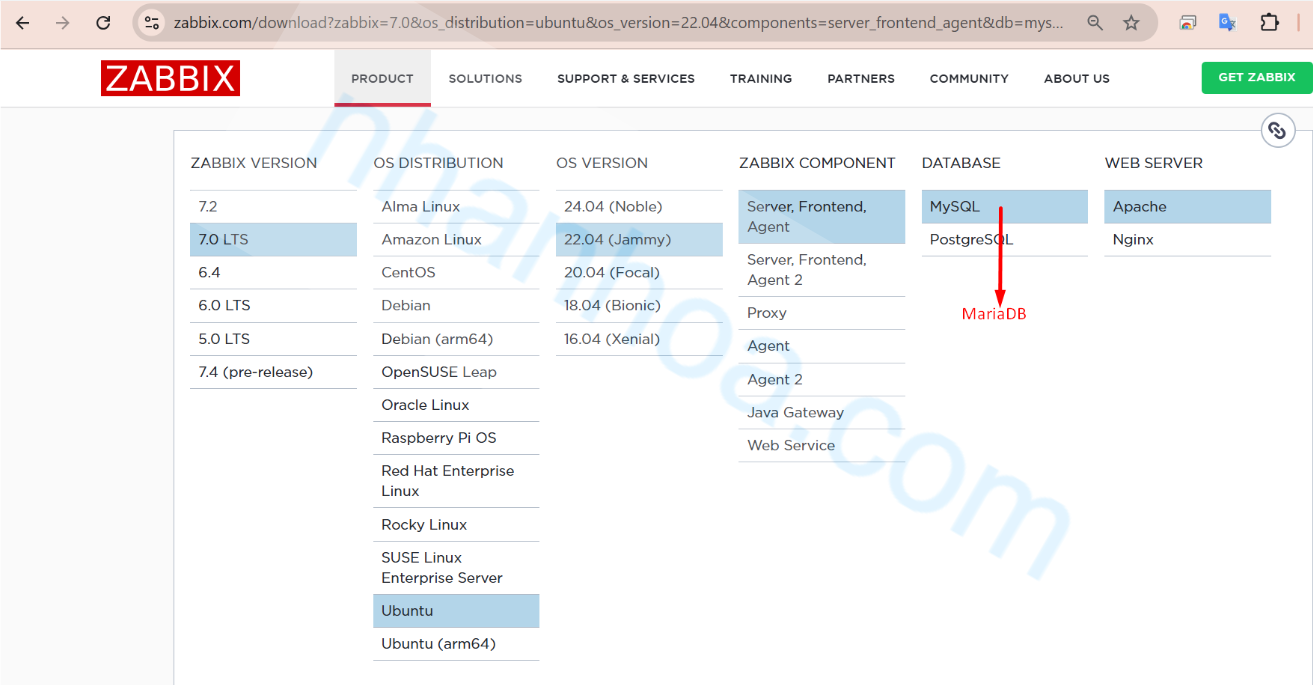
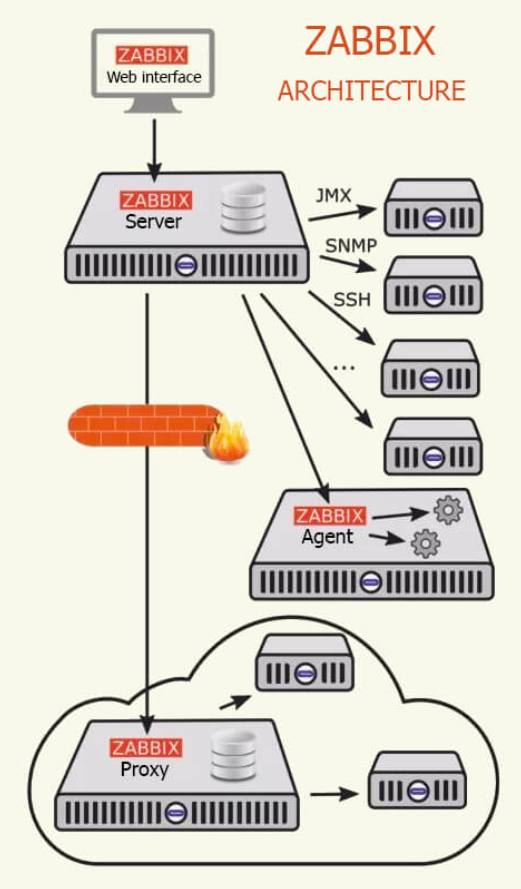
Zabbix là một nền tảng giám sát mã nguồn mở mạnh mẽ. Được sử dụng rộng rãi để theo dõi hiệu suất của hệ thống, thiết bị mạng, ứng dụng và dịch vụ CNTT. Kiến trúc của Zabbix được thiết kế theo mô hình phân tán nhằm đáp ứng các yêu cầu về khả năng mở rộng, tính sẵn sàng cao và hiệu suất xử lý dữ liệu. Bài viết này trình bày chi tiết về các thành phần chính trong hệ thống Zabbix, bao gồm Zabbix Server, Zabbix Agent, Zabbix Proxy, cơ sở dữ liệu, giao diện Web và Cơ Chế Hoạt Động.
Xem thêm: Chính sách phát triển và vòng đời của Zabbix
Với vai trò là kỹ thuật hệ thống có rất nhiều công cụ có thể áp dụng để giám sát hệ thống cho khách hàng trong đó zabbix là một công cụ mạnh mẽ phù hợp lựa chọn sử dụng. Để đảm bảo tính ổn định và bảo mật, việc nắm rõ Life Cycle và Release Policy của các dịch vụ, ở đây là Zabbix là vô cùng quan trọng.
Life Cycle Zabbix có chu kỳ phát triển rõ ràng, với các bản phát hành được chia thành hai loại chính:

Apache Kafka đã trở thành công cụ hàng đầu trong xử lý dữ liệu thời gian thực và hệ thống phân tán. Bài viết này giải thích chi tiết về Kafka, cách thức hoạt động, ứng dụng thực tế, và lý do bạn nên sử dụng nó.

Trong kỷ nguyên dữ liệu lớn (Big Data), việc xử lý dữ liệu nhanh chóng, hiệu quả và đáng tin cậy trở thành nhu cầu thiết yếu của các doanh nghiệp. Hệ thống xử lý dữ liệu phân tán (Distributed Data Processing System) là giải pháp hàng đầu để giải quyết vấn đề này. Bằng cách phân tán khối lượng công việc xử lý dữ liệu trên nhiều máy tính khác nhau, hệ thống này mang lại hiệu suất cao, khả năng mở rộng linh hoạt và độ tin cậy vượt trội.
Trong phần này, chúng ta sẽ cùng khám phá vị trí lưu trữ và các tệp log trong ba hệ thống quản trị web phổ biến: Cpanel, DirectAdmin và Plesk. Việc theo dõi và phân tích log sẽ giúp quản trị viên phát hiện lỗi sớm, xử lý sự cố nhanh và tối ưu hiệu suất hệ thống.

Trước khi đi sâu vào loạt bài chi tiết về Graylog – công cụ mạnh mẽ cho việc thu thập và phân tích log – chúng ta cần nắm vững bước cơ bản nhất: định vị và hiểu cấu trúc các tệp log trong hệ thống. Dù bạn sử dụng hệ điều hành Linux hay Windows, việc biết chính xác vị trí lưu trữ log như log SSH, sự kiện bảo mật hay log lỗi hệ thống sẽ giúp bạn cấu hình Graylog hiệu quả, từ đó giám sát và bảo mật hệ thống một cách chủ động.

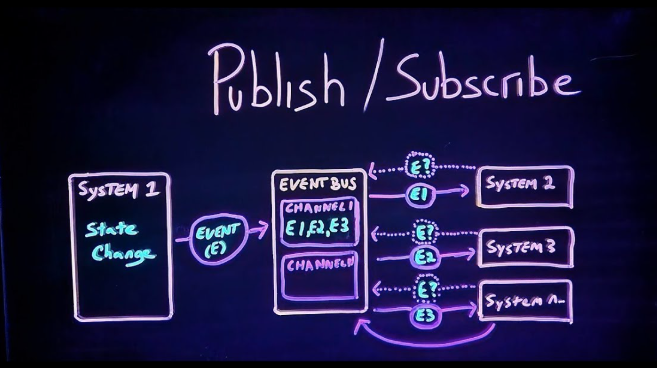
Publisher-Subscriber (Pub-Sub) là một mô hình giao tiếp không đồng bộ, trong đó Publisher (Người xuất bản) gửi thông điệp mà không cần biết ai sẽ nhận, và Subscriber (Người đăng ký) chỉ nhận thông điệp mà họ quan tâm thông qua một hệ thống trung gian gọi là Message Broker.
© 2025 Trang tin tức từ Cloud365 – Nhân Hòa
Theme by Anders Noren — Up ↑
Recent Comments