Trong phần trước chúng ta đã cùng tìm hiểu về mô hình, cũng như tại sao nên sử dụng Kafka. Bài viết này chúng ta sẽ khám phá cách Kafka hoạt động, kiến trúc của nó và các thành phần chính.

1. Kafka Events
Kafka Events (hay còn gọi là messages) là đơn vị dữ liệu nhỏ nhất trong hệ thống Kafka. Mỗi sự kiện đại diện cho một hành động hoặc thông tin được gửi qua Kafka, chẳng hạn như giao dịch, cập nhật trạng thái, hoặc nhật ký hệ thống.
Cách hoạt động
- Một sự kiện bao gồm key, value, timestamp, và các metadata tùy chọn.
- Sự kiện được gửi từ Producers đến Topics và được Consumers đọc lại.
Ví dụ minh họa
Giả sử một ứng dụng thương mại điện tử gửi sự kiện:
- Key: ID đơn hàng (ví dụ: “Order123”)
- Value: Chi tiết đơn hàng (ví dụ: “Người mua: Nam, Sản phẩm: Áo, Giá: 200k”)
- Timestamp: Thời gian đặt hàng (ví dụ: “2025-03-05 10:00:00”).
2. Kafka Topics
Topics là các danh mục logic nơi các sự kiện được lưu trữ và phân loại. Mỗi Topic giống như một “kênh” mà Producers gửi dữ liệu vào và Consumers đọc dữ liệu từ đó
Cách hoạt động
- Một Topic có thể chứa nhiều sự kiện liên quan.
- Dữ liệu trong Topic được tổ chức thành các Partitions (phân vùng).
Topics hoạt động như một hàng đợi phân tán (distributed queue), hỗ trợ nhiều Producers và Consumers cùng lúc.
Bước 1: Topic được tạo với số lượng Partition xác định (ví dụ: 4 Partition).
Bước 2: Producer gửi sự kiện đến Topic.
Bước 3: Kafka phân phối sự kiện vào Partition dựa trên Key hoặc ngẫu nhiên.
Bước 4: Consumer đăng ký vào Topic và đọc từ các Partition.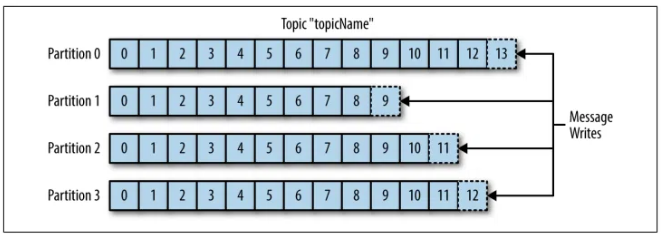
Ví dụ minh họa
- Topic “Orders” có 4 Partition.
- Sự kiện “Order123” được gửi vào Partition 1.
- Consumer Group đọc song song từ cả 3 Partition.
3. Kafka Brokers và Kafka Clusters
- Broker: Một máy chủ Kafka đơn lẻ, chịu trách nhiệm lưu trữ và quản lý dữ liệu trong Topics.
- Cluster: Một nhóm các Brokers hoạt động cùng nhau để tăng khả năng mở rộng và độ tin cậy.
Cách hoạt động
- Mỗi Broker lưu trữ một số Partition của Topic.
- Cluster sử dụng cơ chế sao chép (replication) để đảm bảo dữ liệu không bị mất nếu một Broker gặp sự cố.
Bước 1: Cluster khởi động với nhiều Broker (ví dụ: 3 Broker).
Bước 2: Topic được phân phối Partition lên các Broker.
Bước 3: Broker Leader nhận sự kiện từ Producer và ghi vào log.
Bước 4: Broker Follower sao chép dữ liệu từ Leader qua Replication.
Bước 5: Consumer kéo dữ liệu từ Broker Leader.Ví dụ minh họa
- Broker 1 (Leader) lưu Partition 1, Broker 2 sao chép.
- Nếu Broker 1 lỗi, Broker 2 được Zookeeper bầu làm Leader.
4. Kafka Partitions và Kafka Replication
- Partitions: Phân vùng là cách Kafka chia nhỏ dữ liệu trong một Topic để tăng hiệu suất và khả năng song song.
- Replication: Sao chép dữ liệu giữa các Broker để đảm bảo tính sẵn sàng cao (high availability).
Cách hoạt động
- Mỗi Partition là một log tuần tự, chỉ được ghi vào cuối (append-only).
- Replication tạo bản sao của Partition trên nhiều Broker, với một Leader và các Follower.
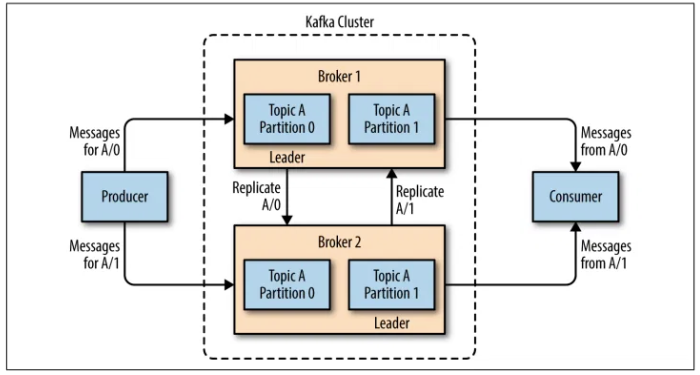
Bước 1: Topic chia thành nhiều Partition.
Bước 2: Producer gửi sự kiện, Partition được chọn dựa trên Key.
Bước 3: Partition Leader trên Broker 1 ghi sự kiện.
Bước 4: Partition Follower trên Broker 2, 3 sao chép từ Leader.
Bước 5: Consumer đọc từ Partition Leader.Ví dụ minh họa
- Partition 1 (Leader: Broker 1) chứa “Order123”.
- Partition 1 sao chép sang Broker 2 (Follower).
5. Kafka Producers
Producers là các ứng dụng hoặc hệ thống gửi sự kiện vào Kafka Topics.
Cách hoạt động
- Producers đẩy sự kiện đến Topic, có thể chỉ định Partition cụ thể bằng Key hoặc để Kafka tự động phân phối.
- Hỗ trợ gửi đồng bộ (sync) hoặc bất đồng bộ (async).
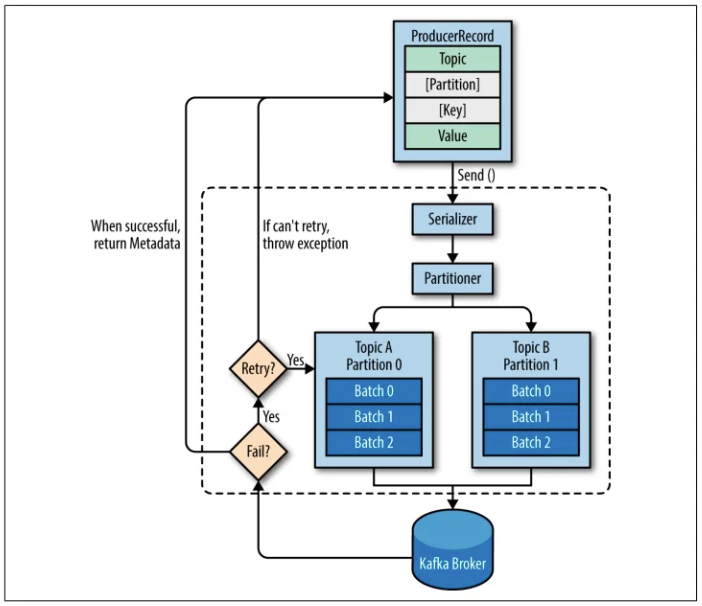
1. Tạo ProducerRecord (Topic, Value, [Partition, Key]).
- Ví dụ:
+ Topic: "Orders"
+ Value: "Đơn hàng: Áo, Giá: 200k"
+ Key: "Order123" (tùy chọn)
+ Partition: Không chỉ định (tùy chọn
2. Serialize Key/Value thành ByteArrays.
- Ví dụ:
+ Key "Order123" → [79, 114, 100, 101, 114, 49, 50, 51] (byte array).
+ Value "Đơn hàng: Áo, Giá: 200k" → [Đ, ơ, n, ...] (byte array UTF-8).
3. Partitioner chọn Partition (dựa trên Key hoặc chỉ định).
- Ví dụ:
+ Không chỉ định Partition → Partitioner dùng Key "Order123" để tính (ví dụ: hash("Order123") % 3 = Partition 1).
+ Nếu chỉ định Partition 2 → Dữ liệu gửi thẳng tới Partition 2.
4. Gửi lô bản ghi tới Broker → Nhận RecordMetadata hoặc lỗi (retry nếu thất bại).
- Ví dụ:
+ Lô bản ghi gửi tới Broker 1 (Partition 1 của Topic "Orders").
+ Broker trả về: RecordMetadata(Topic: "Orders", Partition: 1, Offset: 100).
+ Nếu lỗi (ví dụ: Broker 1 tạm ngắt), Producer retry 3 lần trước khi báo lỗi.6. Kafka Consumers
Consumers là các ứng dụng hoặc hệ thống đọc sự kiện từ Kafka Topics.
Cách hoạt động
- Consumers đăng ký (subscribe) vào một hoặc nhiều Topic.
- Có thể hoạt động trong Consumer Group để phân chia công việc đọc dữ liệu từ các Partition.
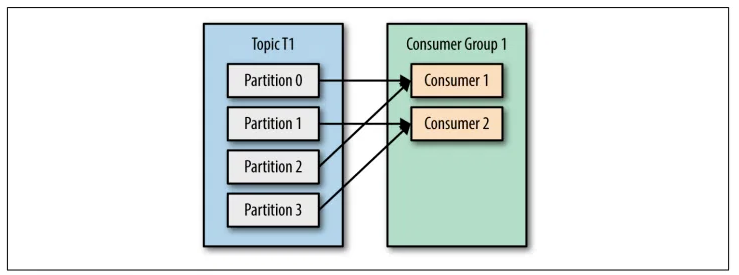
- Đăng ký vào Topic/Group.
- Kafka gán Partition:
- TH1: Consumer < Partition → Một Consumer đọc nhiều Partition.
- TH2: Consumer = Partition → Một Consumer đọc một Partition.
- TH3: Consumer > Partition → Một số Consumer nhàn rỗi.
3. Consumer kéo sự kiện từ Partition.
4. Lưu offset sau khi xử lý.
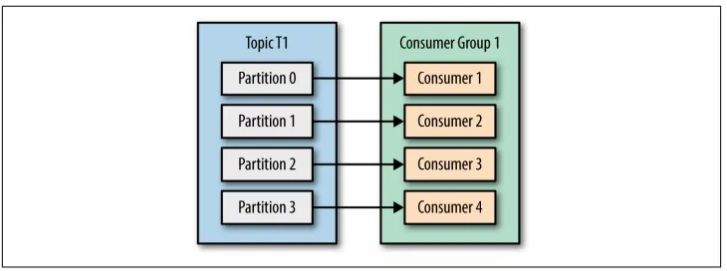
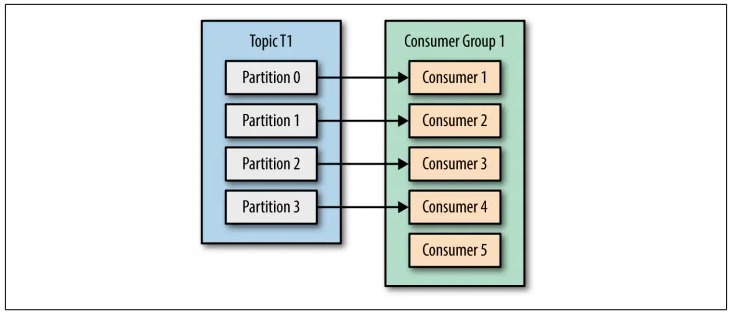
So sánh:
| Trường hợp | Lợi ích | Khuyết điểm |
|---|---|---|
| Consumer < Partition | Tiết kiệm tài nguyên, dễ quản lý | Tải không đều, hiệu suất giảm |
| Consumer = Partition | Cân bằng tải, hiệu suất tối ưu | Ít linh hoạt, khó mở rộng tức thời |
| Consumer > Partition | Dự phòng tốt, sẵn sàng mở rộng | Lãng phí tài nguyên, không tăng hiệu suất |
Ứng dụng thực tế:
- TH1: Dùng khi tài nguyên hạn chế và chấp nhận hiệu suất trung bình (ví dụ: hệ thống nhỏ).
- TH2: Lý tưởng cho hệ thống cần hiệu suất cao và ổn định (ví dụ: xử lý luồng dữ liệu lớn).
- TH3: Phù hợp khi dự đoán Topic sẽ mở rộng trong tương lai hoặc cần độ tin cậy cao (ví dụ: hệ thống quan trọng).
7. Zookeepers
Zookeeper là một dịch vụ quản lý cấu hình phân tán, được Kafka sử dụng để điều phối các Broker trong Cluster.
Cách hoạt động
- Zookeeper lưu trữ metadata (ví dụ: vị trí Partition, trạng thái Broker).
- Giúp bầu chọn Leader cho các Partition và phát hiện lỗi Broker.
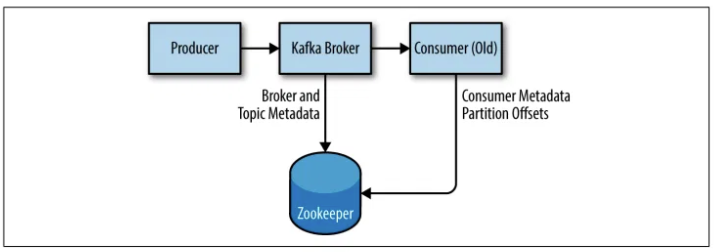
Bước 1: Zookeeper khởi động và kết nối với Kafka Cluster.
Bước 2: Zookeeper lưu metadata (Broker, Partition, Leader).
Bước 3: Broker báo cáo trạng thái cho Zookeeper.
Bước 4: Nếu Broker lỗi, Zookeeper bầu Leader mới từ Follower.
Bước 5: Consumer/Producers truy vấn Zookeeper để tìm Broker.Ví dụ minh họa
Nếu Broker 1 gặp sự cố, Zookeeper phát hiện và chuyển Leader của Partition 1 sang Broker 2.
8. Kafka APIs
Kafka cung cấp các API để tương tác với hệ thống, bao gồm:
- Producer API: Gửi sự kiện.
- Consumer API: Đọc sự kiện.
- Streams API: Xử lý luồng dữ liệu.
- Connect API: Tích hợp với hệ thống bên ngoài.
- Admin API: Quản lý và cấu hình Kafka.
Cách hoạt động
Bước 1: Ứng dụng gọi API (Producer/Consumer/Streams/Connect).
Bước 2: Producer API gửi sự kiện đến Topic.
Bước 3: Consumer API kéo sự kiện từ Topic.
Bước 4: Streams API xử lý dữ liệu luồng (stream processing).
Bước 5: Connect API nhập/xuất dữ liệu từ hệ thống bên ngoài.Ví dụ minh họa
- Sử dụng Producer API để gửi đơn hàng từ ứng dụng Java vào Topic “Orders”.
- Sử dụng Consumer API để đọc dữ liệu từ Topic bằng Python.
9. Kết luận
Apache Kafka là một hệ sinh thái mạnh mẽ với kiến trúc phân tán tối ưu cho xử lý dữ liệu thời gian thực. Từ Kafka Events, Topics, Brokers, đến Producers, Consumers, và các thành phần như Zookeeper hay APIs, mỗi phần đều đóng vai trò quan trọng trong việc đảm bảo hiệu suất, khả năng mở rộng và độ tin cậy. Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về cách Kafka hoạt động và cách áp dụng nó vào thực tế.
Leave a Reply