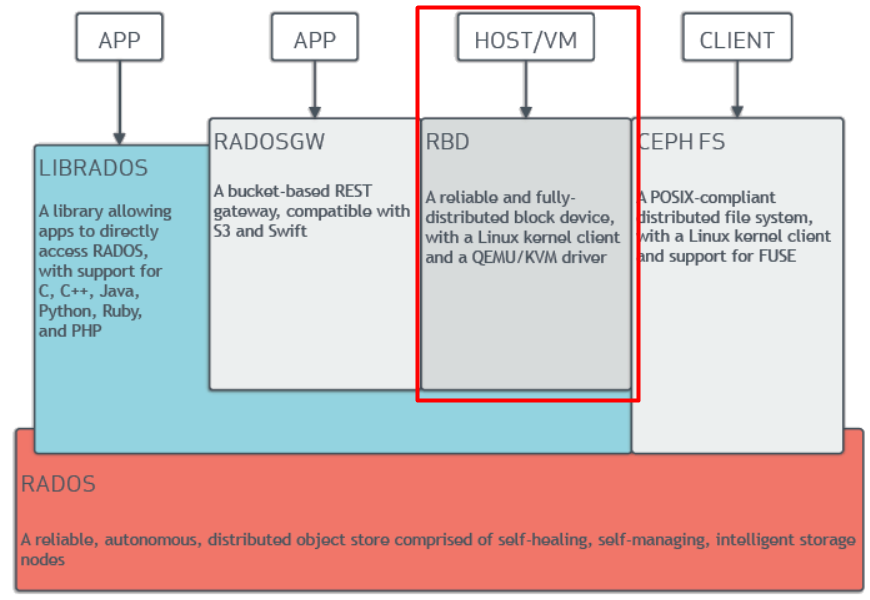
Block stoarge sẽ dùng như thế nào nhỉ?
Trong phần 1, cloud365 đã hướng dẫn bạn triển khai cluser ceph và cấu hình object storage, block storage. Trong phần tiếp theo, chúng tôi sẽ hướng dẫn bạn tạo ra các image RBD (thuật ngữ của CEPH để cấp block storage – hãy hình dung nó chính là ổ cứng được cấp cho các client sử dụng) và cấu hình để máy client có thể sử dụng được. Còn chờ gì nữa! Hãy bắt đầu nào.
Cách dùng block storage được tổng hợp như sau:
- Block storage được dùng để chứa máy ảo trong môi trường cloud hoặc là disk được gắn thêm cho máy ảo hoặc máy chủ thông thường, disk gắn thêm này được cấp ra từ cụm cluser CEPH.
- Muốn dùng block storage thì các client phải có gói phần mềm hỗ trợ, tức là phải cài phần mềm tương đương driver.
- Tốc độ truy cập của block storage nhanh hơn object storage nên phù hợp với các hệ thống đòi hỏi khả năng truy xuất cao như Database, hệ điều hành (chính là OS cài lên disk).
- Đa số các hệ thống cung cấp block storage chỉ cung cấp trong phạm vi khoảng cách ngắn, không như object là có thể qua môi trường internet.
Usecase thực tế dùng block storage
Trong thực tế mà cloud365 đã trải qua thì việc dùng CEPH – Blockstorage là tích hợp với OpenStack hoặc Promox, CloudStack (thậm chí cả VMware) để làm hạ tầng lưu trữ nhằm cung cấp disk cho máy ảo (Cả disk chạy OS và disk gắn thêm). Trong bài lab này chỉ dừng lại ở việc phân tích cách khai báo block để các máy khác có thể dùng được disk (image rdb do CEPH cấp ra). Còn khi tích hợp rồi thì việc cài đặt cho client đã được tự động hóa.
Trên là tổng hợp vắn tắt để bạn có thể hình dung nhanh nhất về block storage được dùng như nào. Chi tiết phân tích về block storage sẽ được tổng hợp ở các bài khác hoặc tra thêm google để rõ hơn nhé (vì đây là bài về LAB).
1. Mô hình LAB
Ở phần 1, mô hình đã bao gồm node client1, nó chính là các máy linux (CentOS, Ubuntu …) sẽ dùng image RDB do cluser CEPH cấp ra.
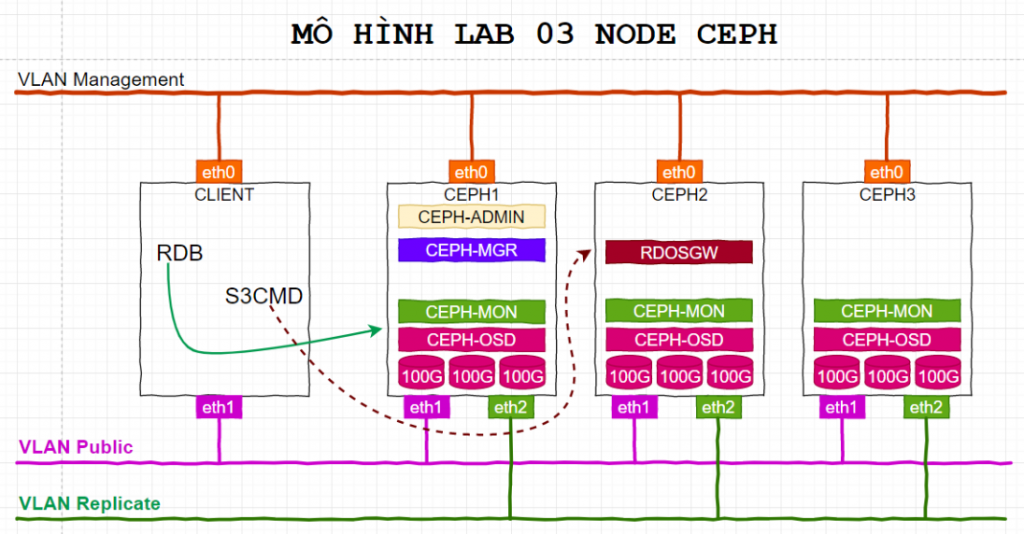
2. IP Planning
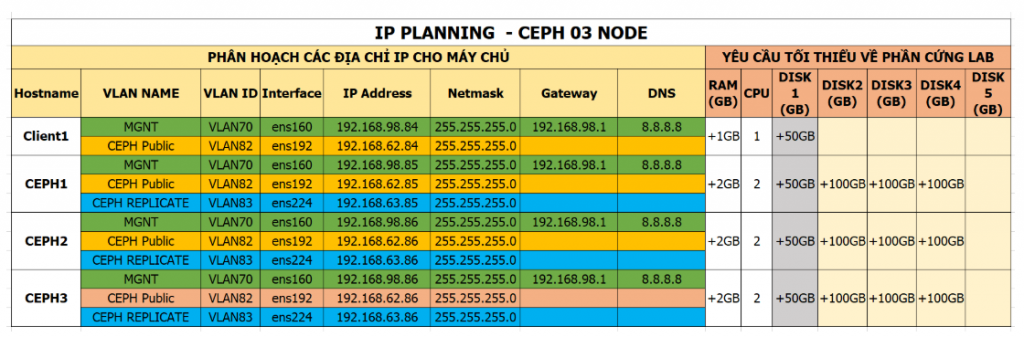
Phần IP Planning cũng tương tự phần 1, máy client sẽ sử dụng 02 NICs. NIC1 – 192.168.98.84 sẽ dùng để điều khiển, quản trị máy client. NIC2 – 192.168.62.84 sẽ dùng để kết nối tới cluster CEPH và sử dụng – nó thuộc VLAN Public.
3. Cấu hình cơ bản cho client1
Lưu ý: muốn LAB phần này thì cần phải hoàn thành xong phần 1.
3.1. Khai báo IP, hostname
Login với quyền root và thực hiện update OS trước khi cài
yum update -yThiết lập hostanme, đặt tên là client1
hostnamectl set-hostname client1Login vào máy client và thiết lập IP theo IP Planning.
echo "Setup IP ens32"
nmcli con modify ens32 ipv4.addresses 192.168.98.84/24
nmcli con modify ens32 ipv4.gateway 192.168.98.1
nmcli con modify ens32 ipv4.dns 8.8.8.8
nmcli con modify ens32 ipv4.method manual
nmcli con modify ens32 connection.autoconnect yes
echo "Setup IP ens33"
nmcli con modify ens33 ipv4.addresses 192.168.62.84/24
nmcli con modify ens33 ipv4.method manual
nmcli con modify ens33 connection.autoconnect yesCấu hình chế độ firewall để tiện trong môi trường lab. Trong môi trường production cần bật firewall hoặc iptables hoặc có biện pháp xử lý khác tương ứng để đảm bảo các vấn đề về an toàn.
sudo systemctl disable firewalld
sudo systemctl stop firewalld
sudo systemctl disable NetworkManager
sudo systemctl stop NetworkManager
sudo systemctl enable network
sudo systemctl start network
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/configKhai báo file /etc/hosts.
cat << EOF > /etc/hosts
127.0.0.1 `hostname` localhost
192.168.62.84 client1
192.168.62.85 ceph1
192.168.62.86 ceph2
192.168.62.87 ceph3
192.168.98.84 client1
192.168.98.85 ceph1
192.168.98.86 ceph2
192.168.98.87 ceph3
EOFKhởi động lại máy trước khi tiếp các bước phía sau.
init 63.2. Cài đặt repos và các gói bổ trợ cho client1
Sau khi khởi động xong, login với quyền root và thực hiện các bước tiếp theo.
Lưu ý: Bước này thực hiện trên client1.
Cài đặt các gói bổ trợ cho client1
yum update -y
yum install epel-release -y
yum install wget bybo curl git -y
yum install python-setuptools -y
yum install python-virtualenv -y
yum update -yCấu hình NTP
yum install -y chrony
systemctl enable chronyd.service
systemctl start chronyd.service
systemctl restart chronyd.service
chronyc sourcesKiểm tra lại thời gian bằng lệnh timedatectl. Nếu đúng giờ chuẩn thì không phải xem lại nữa.
Lưu ý: Nếu bạn có hệ thống NTP nội bộ, hãy cấu hình nó hoặc tham khảo ở đây: https://news.cloud365.vn/?s=ntp
Tạo user là cephuser với mật khẩu là matkhau2019@
useradd cephuser; echo 'matkhau2019@' | passwd cephuser --stdinecho "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
chmod 0440 /etc/sudoers.d/cephuser3.3. Cài đặt các gói cần thiết cho client1 để sụng dụng block storage
Bước này thực hiện cài đặt các gói ceph client để cho node client1 có thể sử dụng được block devie.
Lưu ý: Bước này sẽ login vào node CEPH1 để thực hiện việc cài đặt.
Login vào node CEPH1 với tài khoản cephuser. Hoặc chuyển sang user cephuser bằng lệnh dưới.
su - cephuserDi chuyển vào thư mục my-cluster đã tạo từ phần 1.
cd my-clusterThực hiện copy key-pair đã tạo ở phần 1 từ ceph1 sang client1
ssh-copy-id cephuser@client1Thực hiện cài đặt các gói của ceph cho client1
ceph-deploy install --release nautilus client1Kết quả
[client1][DEBUG ] Complete!
[client1][INFO ] Running command: sudo ceph --version
[client1][DEBUG ] ceph version 14.2.3 (0f776cf838a1ae3130b2b73dc26be9c95c6ccc39) nautilus (stable)Thực hiện deploy node client1
ceph-deploy admin client1Kết quả
cephuser@ceph1:~/my-cluster$ ceph-deploy admin client1
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephuser/.cephdeploy.conf
......
[ceph_deploy.admin][DEBUG ] Pushing admin keys and conf to client1
[client1][DEBUG ] connection detected need for sudo
[client1][DEBUG ] connected to host: client1
[client1][DEBUG ] detect platform information from remote host
[client1][DEBUG ] detect machine type
[client1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.confĐứng trên node CEPH1 để phân quyền cho file /etc/ceph/ceph.client.admin.keyring cho node client1
ssh cephuser@client1 'sudo chmod +r /etc/ceph/ceph.client.admin.keyring'3.4. Cấu hình RBD cho Client sử dụng
Thực hiên trên node ceph1
Khai báo pool tên là rbd để client sử dụng. Tên pool này khá đặc biệt vì nó là pool block storage mặc định của CEPH. Nếu trong các lệnh ko đưa tùy chọn -p ten_pool thì CEPH sẽ làm việc với pool này.
ceph osd pool create rbd 128rbd pool init rbd
Kiểm tra pool vừa tạo xem đã có hay chưa bằng lệnh ceph osd pool ls
ceph osd pool lsKết quả lệnh trên sẽ là:
cephuser@ceph1:~/my-cluster$ ceph osd pool ls
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
rbd
Tới đây đã thiết lập rbd pool xong trên node CEPH1. Chuyển sang client để sử dụng các images (tạm hiểu là các disk)
Lưu ý: Bước này thực hiện trên client1
Đứng trên node cephclient1 thực hiện tạo một image có tên là disk01 với dung lượng là 10GB, image này sẽ nằm trong pool có tên là rdbpool vừa tạo ở trên.
rbd create disk01 --size 10G --image-feature layeringDùng lệnh liệt kê các images để kiểm tra lại xem các images RDB đã được tạo hay chưa. Lưu ý, trong phần lab này nên đặt tên pool là rbd để thao tác đúng các bước, việc đặt tên khác sẽ được hướng dẫn ở phần khác.
rbd ls -lKết quả lệnh rbd ls -l -p rbd
[root@client1 ~]# rbd ls -l -p rbd
NAME SIZE PARENT FMT PROT LOCK
disk01 10 GiB 2Tới đây ta mới chỉ dừng lại việc tạo ra image, việc tiếp theo cần phải gắn nó vào máy ảo và format, sau đó tiếp tục mount vào thư mục cần thiết.
Thực hiện map images đã được tạo tới một disk của máy client
rbd map disk01 Kết quả
[root@client1 ~]# rbd map disk01
/dev/rbd0Lệnh trên sẽ thực hiện map images có tên là disk01 tới một thiết bị trên client, thiết bị này sẽ được đặt tên là /dev/rdbX. Trong đó X sẽ bắt đầu từ 0 và tăng dần lên. Nếu muốn biết về việc quản lý thiết bị trong linux thì đọc thêm các tài liệu của Linux nhé bạn đọc ơi.
Thực hiện kiểm tra xem images RBD có tên là disk01 đã được map hay chưa.
rbd showmappedKết quả
[root@client1 ~]# rbd showmapped
id pool namespace image snap device
0 rbd disk01 - /dev/rbd0Hoặc kiểm tra bằng lệnh lsblk
[root@client1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 100G 0 disk
├─vda1 252:1 0 512M 0 part /boot
└─vda2 252:2 0 99.5G 0 part
├─VolGroup00-LogVol01 253:0 0 97.5G 0 lvm /
└─VolGroup00-LogVol00 253:1 0 2G 0 lvm [SWAP]
rbd0 251:0 0 10G 0 diskTới đây máy client chưa thể sử dụng ổ được map vì chưa được phân vùng, tiếp tục thực hiện bước phân vùng và mount vào một thư mục nào đó để sử dụng. Thời gian thực hiện lệnh dưới sẽ cần chờ từ 10-30 giây.
sudo mkfs.xfs /dev/rbd0Kết quả
[root@client1 ~]# sudo mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=16, agsize=163840 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Thực hiện mount vào thư mục /mtn
sudo mount /dev/rbd0 /mntKiểm tra lại xem đã mount được hay chưa bằng lệnh df -hT
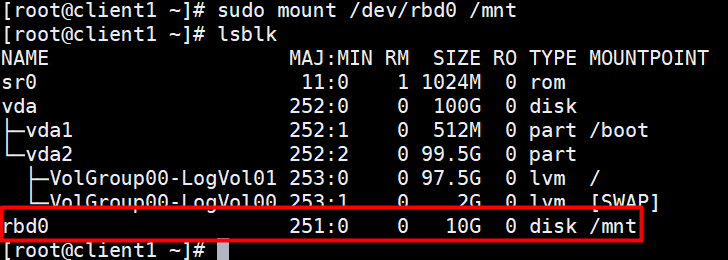
Kích hoạt rdb map
systemctl start rbdmap
systemctl enable rbdmap
systemctl status rbdmapLưu ý: Vì mount chưa được khai báo trong fstab nên khi khởi động lại máy client thì thao tác mount này sẽ bị mất, nếu muốn không bị mất thì cần phải khai báo thêm trong fstab nhé. Thực hiện các bước sau để map
Sửa file vi /etc/ceph/rbdmap bằng việc thêm dòng rbd/disk01 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring vào cuối file. Nội dung của file /etc/ceph/rbdmap như dưới
[root@client1 ~]# cat /etc/ceph/rbdmap
# RbdDevice Parameters
#poolname/imagename id=client,keyring=/etc/ceph/ceph.client.keyring
rbd/disk01 id=admin,keyring=/etc/ceph/ceph.client.admin.keyringTrong đó:
rbd/disk01:dược khai báo theo cú phápten_pool/ten_imageid:là giá trịadminkeyring:là đường dẫn file key được tạo ở bước trước đó.
Sửa file /etc/fstab bằng việc khai báo đường dẫn của device và thư mục được mount. Thêm dòng dưới vào cuối cùng của file.
/dev/rbd/rbd/disk01 /mnt xfs noauto 0 0Nội dung của file /etc/fstab sẽ có dạng như sau
[root@client1 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Sun Sep 2 16:46:37 2018
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=a03e4ac4-d684-4e31-b8d6-93fbdf6d8d02 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
/dev/rbd/rbd/disk01 /mnt xfs noauto 0 0Đường dẫn của device sẽ có dạng: /dev/rbd/ten_pool/ten_image. Trong ví dụ này chính là /dev/rbd/rbd/disk01 và /mnt là thư mục được mount.
Sau khi khai báo xong, có thể khởi động lại và kiểm tra bằng lệnh lsblk để xem disk01 còn được gắn vào hay không, nếu không thì hãy kiểm tra lại các bước trên :).
Hoặc
Quay lại dashboard quan sát, ta sẽ thấy ở tab block thông tin về image được tạo. (ngoài ra có thể xem các thông số khác, tự khám phá tiếp nhé).
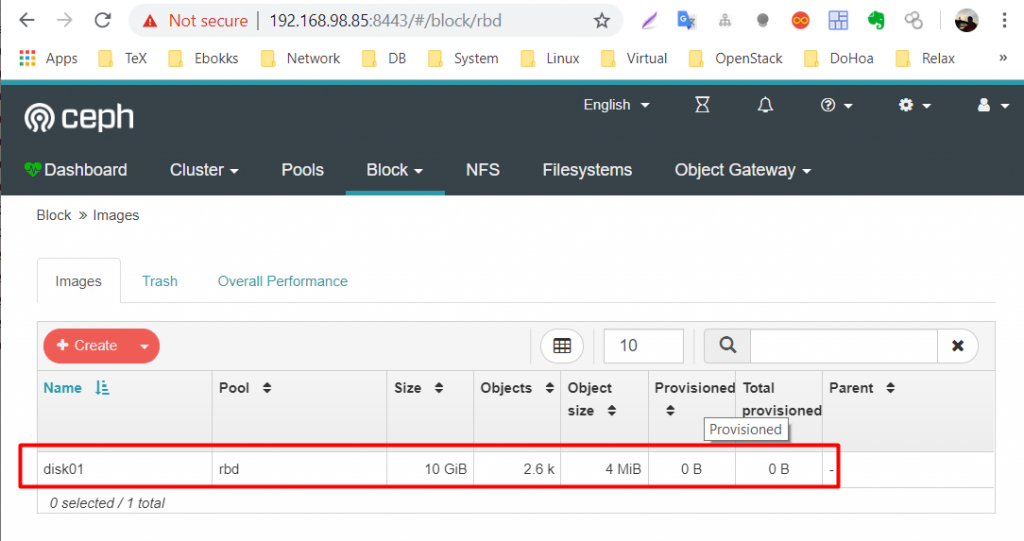
Thực hiện tạo ra pool thứ 2 cho block storage
Mặc định nếu trong các lệnh rbd để vận hành block storae, nếu ta không chỉ định thì pool name sẽ có tên là rdb. Trong phần này tôi sẽ mở rộng với pool khác để các bạn phân biệt.
Đứng ở ceph1 Tạo pool tiếp theo cho block storage với tên là rbdpool.
ceph osd pool create rbdpool 128
rbd pool init rbdpoolKiểm tra lại các pool đã được tạo hay chưa bằn lệnh ceph osd pool ls. Ta có kết quả dưới.
cephuser@ceph1:~/my-cluster$ ceph osd pool ls
.rgw.root
default.rgw.control
default.rgw.meta
default.rgw.log
rbdpool
rbdChuyển sang node client1 thực hiện các bước dưới.
Thực hiện khai báo cho client sử dụng pool có tên là rbdpool. Đứng trên client1 thực hiện với tùy chọn -p rbdpoll
rbd create disk02 --size 10G --image-feature layering -p rbdpoolKiểm tra image có tên là disk02 xem được tạo hay chưa bằng lệnh rbd ls -l -p rbdpool . Kết quả là
[root@client1 ~]# rbd ls -l -p rbdpool
NAME SIZE PARENT FMT PROT LOCK
disk02 10 GiB 2Thực hiện map image disk02 để client1 sử dụng. Lưu ý chỉ định tùy chọn -p rbdpool
rbd map disk02 -p rbdpoolKiểm tra lại bằng lệnh rbd showmapped
[root@client1 ~]# rbd showmapped
id pool namespace image snap device
0 rbd disk01 - /dev/rbd0
1 rbdpool disk02 - /dev/rbd1Thực hiện format /dev/rdb1 để bắt đầu sử dụng.
sudo mkfs.xfs /dev/rbd1Thực hiện mount thư mục /opt của client1 để dùng.
sudo mount /dev/rbd1 /optThử ghi dữ liệu và quan sát ở thư mục /opt
[root@client1 ~]# echo "Cloud365 chao cac ban" > /opt/ceph.txt
[root@client1 ~]# cat /opt/ceph.txt
Cloud365 chao cac ban
Như vậy cần lưu ý nếu đặt tên pool cho ceph là khác thì phải chỉ định tên pool trong các lệnh.
Kết luận
Tới đây mình đã hướng dẫn xong việc các bạn cấp phát Image RBD và khai báo để client có thể sử dụng. Xin lưu ý đây chỉ là LAB để phân tích các bước dùng block storage của CEPH như nào thôi nhé vì trong thực tế ít khi dùng kiểu thủ công như này. Thay vào đó là sẽ là các bước tích hợp với các nền tảng kiểu như OpenStack (hoặc VMware mình đã từng nghe thôi chứ chưa làm 😀 ) để làm nơi lưu trữ tập trung. Phần hướng dẫn này sẽ là phần nâng cao và nằm ở một chuỗi bài khác.
Team Cloud365 rất vui khi được chia sẻ các tìm hiểu của mình với mọi người. Hi vọng sẽ nhận được các phản hồi và góp ý từ các bạn. Trân trọng cảm ơn.
Tham khảo phần 1 tại đây
Leave a Reply